In this tutorial, you will learn how to break deep learning models using image-based adversarial attacks. We will implement our adversarial attacks using the Keras and TensorFlow deep learning libraries.

Imagine it’s twenty years from now. Nearly all cars and trucks on the road have been replaced with autonomous vehicles, powered by Artificial Intelligence, deep learning, and computer vision — every turn, lane switch, acceleration, and brake is powered by a deep neural network.
Now, imagine you’re on the highway. You’re sitting in the “driver’s seat” (is it really a “driver’s seat” if the car is doing the driving?) while your spouse is in the passenger seat, and your kids are in the back.
Looking ahead, you see a large sticker plastered on the lane your car is driving in. It looks innocent enough. It’s just a big print of the graffiti artist Banksy’s popular Girl with Balloon work. Some high school kids probably just put it there as part of a weird dare/practical joke.

A split second later, your car reacts by violently breaking hard and then switching lanes as if the large art print plastered on the road is a human, an animal, or another vehicle. You’re jerked so hard that you feel the whiplash. Your spouse screams while Cheerios from your kid in the backseat rocket forward, hitting the windshield and bouncing all over the center console.
You and your family are safe … but it could have been a lot worse.
What happened? Why did your self-driving car react that way? Was it some sort of weird “bug” in the code/software your car is running?
The answer is that the deep neural network powering the “sight” component of your vehicle just saw an adversarial image.
Adversarial images are:
- Images that have pixels purposely and intentionally perturbed to confuse and deceive models …
- … but at the same time, look harmless and innocent to humans.
These images cause deep neural networks to purposely make incorrect predictions. Adversarial images are perturbed in such a way that the model is unable to correctly classify them.
In fact, it may be impossible for humans to visually identify a normal image from one that has been visually perturbed for an adversarial attack — essentially, the two images will appear identical to the human eye.
While not an exact (or correct) comparison, I like to explain adversarial attacks in the context of image steganography. Using steganography algorithms, we can embed data (such as plaintext messages) in an image without distorting the appearance of the image itself. This image can be innocently transmitted to the receiver, who can then extract the hidden message from the image.
Similarly, adversarial attacks embed a message in an input image — but instead of a plaintext message meant for human consumption, an adversarial attack instead embeds a noise vector in the input image. This noise vector is purposely constructed to fool and confuse deep learning models.
But how do adversarial attacks work? And how can we defend against them?
This tutorial, along with the rest of the posts in this series, will cover that exact same question.
To learn how to break deep learning models with adversarial attacks and images using Keras/TensorFlow, just keep reading.
Adversarial images and attacks with Keras and TensorFlow
In the first part of this tutorial, we’ll discuss what adversarial attacks are and how they impact deep learning models.
From there, we’ll implement three separate Python scripts:
- The first one will be a helper utility used to load and parse class labels from the ImageNet dataset.
- Our next Python script will perform basic image classification using ResNet, pre-trained on the ImageNet dataset (thereby demonstrating “standard” image classification).
- The final Python script will perform an adversarial attack and construct an adversarial image that purposely confuses our ResNet model, even though the two images look identical to the human eye.
Let’s get started!
What are adversarial images and adversarial attacks? And how to they impact deep learning models?

In 2014, Goodfellow et al. published a paper entitled Explaining and Harnessing Adversarial Examples, which showed an intriguing property of deep neural networks — it’s possible to purposely perturb an input image such that the neural network misclassifies it. This type of perturbation is called an adversarial attack.
The classic example of an adversarial attack can be seen in Figure 2 above. On the left, we have our input image which our neural network correctly classifies as “panda” with 57.7% confidence.
In the middle, we have a noise vector, which to the human eye, appears to be random. However, it’s far from random.
Instead, the pixels in noise vector are “equal to the sign of the elements of the gradient of the cost function with the respect to the input image” (Goodfellow et al.).
We then add this noise vector to the input image, which produces the output (right) in Figure 2. To us, this image appears identical to the input; however, our neural network now classifies the image as a “gibbon” (a small ape, similar to a monkey) with 99.7% confidence.
Creepy, right?
A brief history of adversarial attacks and images
Adversarial machine learning is not a new field, nor are these attacks specific to deep neural networks. In 2006, Barreno et al. published a paper entitled Can Machine Learning Be Secure? This paper discussed adversarial attacks, including proposed defenses against them.
Back in 2006, the top state-of-the-art machine learning models included Support Vector Machines (SVMs) and Random Forests (RFs) — it’s been shown that both these types of models are susceptible to adversarial attacks.
With the rise in popularity of deep neural networks starting in 2012, it was hoped that these highly non-linear models would be less susceptible to attacks; however, Goodfellow et al. (among others) dashed these hopes.
It turns out that deep neural networks are susceptible to adversarial attacks, just like their predecessors.
For more information on the history of adversarial attacks, I recommend reading Biggio and Roli’s excellent 2017 paper, Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning.
Why are adversarial attacks and images a problem?
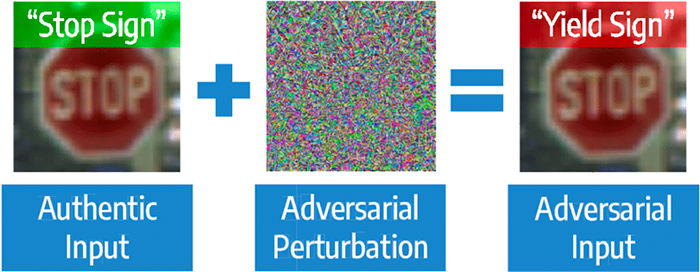
The example at the top of this tutorial outlined why adversarial attacks could cause massive damage to health, life, and property.
Examples with less severe consequences could be a group of hackers identifies that a specific model is being used by Google for spam filtering in Gmail, or a given model is being used by Facebook to automatically detect pornography in their NSFW filter.
If these hackers wanted to flood Gmail users with emails that bypass Gmail’s spam filters, or upload massive amounts of pornography to Facebook that bypasses their NSFW filters, they could theoretically do so.
These are all examples of adversarial attacks with less consequences.
An adversarial attack in a scenario with higher consequences could include hacker-terrorists identifying that a specific deep neural network is being used for nearly all self-driving cars in the world (imagine if Tesla had a monopoly on the market and was the only self-driving car producer).
Adversarial images could then be strategically placed along roads and highways, causing massive pileups, property damage, and even injury/death to passengers in the vehicles.
The limit to adversarial attacks is only limited by your imagination, your knowledge of a given model, and how much access you have to the model itself.
Can we defend against adversarial attacks?
The good news is that we can help reduce the impact of adversarial attacks (but not necessarily eliminate them completely).
That topic won’t be covered in today’s tutorial, but will be covered in a future tutorial on PyImageSearch.
Configuring your development environment
To configure your system for this tutorial, I recommend following either of these tutorials:
Either tutorial will help you configure your system with all the necessary software for this blog post in a convenient Python virtual environment.
That said, are you:
- Short on time?
- Learning on your employer’s administratively locked laptop?
- Wanting to skip the hassle of fighting with package managers, bash/ZSH profiles, and virtual environments?
- Ready to run the code right now (and experiment with it to your heart’s content)?
Then join PyImageSearch Plus today! Gain access to PyImageSearch tutorial Jupyter Notebooks that run on Google’s Colab ecosystem in your browser — no installation required!
Project structure
Start by using the “Downloads” section of this tutorial to download the source code and example images. From there, let’s inspect our project directory structure.
$ tree --dirsfirst . ├── pyimagesearch │ ├── __init__.py │ ├── imagenet_class_index.json │ └── utils.py ├── adversarial.png ├── generate_basic_adversary.py ├── pig.jpg └── predict_normal.py 1 directory, 7 files
Inside the pyimagesearch module, we have two files:
imagenet_class_index.jsonutils.py: Contains a simple Python helper function used to load and parse theimagenet_class_index.json.
We then have two Python scripts that we’ll be reviewing today:
predict_normal.py: Accepts an input image (pig.jpg), loads our ResNet50 model, and classifies it. The output of this script will be the ImageNet class label index of the predicted class label.generate_basic_adversary.pypredict_normal.pyscript, we’ll construct an adversarial attack that is able to fool ResNet. The output of this script (adversarial.png) will be saved to disk.
Ready to implement your first adversarial attack with Keras and TensorFlow?
Let’s dive in.
Our ImageNet class label/index helper utility
Before we can perform either normal image classification or classification with an image perturbed via an adversarial attack, we first need to create a Python helper function used to load and parse the class labels of the ImageNet dataset.
We have provided a JSON file that contains the ImageNet class label indexes, identifiers, and human-readable strings inside the imagenet_class_index.json file in the pyimagesearch module of our project directory structure.
I’ve included the first few lines of this JSON file below:
{
"0": [
"n01440764",
"tench"
],
"1": [
"n01443537",
"goldfish"
],
"2": [
"n01484850",
"great_white_shark"
],
"3": [
"n01491361",
"tiger_shark"
],
...
"106": [
"n01883070",
"wombat"
],
...
Here you can see that the file is a dictionary. The key to the dictionary is the integer class label index, while the value is 2-tuple consisting of:
- The ImageNet unique identifier for the label
- The human-readable class label
Our goal is to implement a Python function that will parse the JSON file by:
- Accepting an input class label
- Returning the integer class label index of the corresponding label
Essentially, we are inverting the key/value relationship in the imagenet_class_index.json file.
Let’s start implementing our helper function now.
Open up the utils.py file in the pyimagesearch module, and insert the following code:
# import necessary packages import json import os def get_class_idx(label): # build the path to the ImageNet class label mappings file labelPath = os.path.join(os.path.dirname(__file__), "imagenet_class_index.json")
Lines 2 and 3 import our required Python packages. We’ll be using the json Python module to load our JSON file, while the os package will be used to construct file paths, agnostic of which operating system you are using.
We then define our get_class_idx helper function. The goal of this function is to accept an input class label and then obtain the integer index of the prediction (i.e., which index out of the 1,000 class labels that a model trained on ImageNet would be able to predict).
Line 7 constructs the path to the imagenet_class_index.json, which lives inside the pyimagesearch module.
Let’s load the contents of that JSON file now:
# open the ImageNet class mappings file and load the mappings as
# a dictionary with the human-readable class label as the key and
# the integer index as the value
with open(labelPath) as f:
imageNetClasses = {labels[1]: int(idx) for (idx, labels) in
json.load(f).items()}
# check to see if the input class label has a corresponding
# integer index value, and if so return it; otherwise return
# a None-type value
return imageNetClasses.get(label, None)
Lines 13-15 open the labelPath file and proceed to invert the key/value relationship such that the key is the human-readable label string and the value is the integer index that corresponds to that label.
In order to obtain the integer index for the input label, we make a call to the .get method of the imageNetClasses dictionary (Line 20) — this call will return either:
- The integer index of the label (if it exists in the dictionary)
- And if the
labeldoes not exist inimageNetClasses, it will returnNone
This value is then returned to the calling function.
Let’s put our get_class_idx helper function to work in the following section.
Normal image classification without adversarial attacks using Keras and TensorFlow
With our ImageNet class label/index helper function implemented, let’s first create an image classification script that performs basic classification with no adversarial attacks.
This script will demonstrate that our ResNet model is performing as we would it expect it to (i.e., making correct predictions). Later in this tutorial, you’ll discover how to construct an adversarial image such that it confuses ResNet.
Let’s get started with our basic image classification script — open up the predict_normal.py file in your project directory structure, and insert the following code:
# import necessary packages from pyimagesearch.utils import get_class_idx from tensorflow.keras.applications import ResNet50 from tensorflow.keras.applications.resnet50 import decode_predictions from tensorflow.keras.applications.resnet50 import preprocess_input import numpy as np import argparse import imutils import cv2
We import our required Python packages on Lines 2-9. These will all look fairly standard to you if you’ve ever worked with Keras, TensorFlow, and OpenCV before.
That said, if you are new to Keras and TensorFlow, I strongly encourage you to read my Keras Tutorial: How to get started with Keras, Deep Learning, and Python guide. Additionally, you may want to read my book Deep Learning for Computer Vision with Python to obtain a deeper understanding of how to train your own custom neural networks.
With all that said, take notice of Line 2, where we import our get_class_idx function, which we defined in the previous section — this function will allow us to obtain the integer index of the top predicted label from our ResNet50 model.
Let’s move on to defining our preprocess_image helper function:
def preprocess_image(image): # swap color channels, preprocess the image, and add in a batch # dimension image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = preprocess_input(image) image = cv2.resize(image, (224, 224)) image = np.expand_dims(image, axis=0) # return the preprocessed image return image
The preprocess_image method accepts a single required argument, the image that we wish to preprocess.
We preprocess the image by:
- Swapping the image from BGR to RGB channel ordering
- Calling the
preprocess_inputimage function, which performs ResNet50-specific preprocessing and scaling - Resizing the image to 224×224
- Adding in a batch dimension
The preprocessed image is then returned to the calling function.
Next, let’s parse our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
We only need a single command line argument here, --image, which is the path to our input image residing on disk.
If you’ve never worked with command line arguments and argparse before, I suggest you read the following tutorial.
Let’s now load our input image from disk and preprocess it:
# load image from disk and make a clone for annotation
print("[INFO] loading image...")
image = cv2.imread(args["image"])
output = image.copy()
# preprocess the input image
output = imutils.resize(output, width=400)
preprocessedImage = preprocess_image(image)
A call to cv2.imread loads our input image from disk. We clone it on Line 31 so we can later draw on it/annotate it with the final output class label prediction.
We resize the output image to have a width of 400 pixels, such that it fits on our screen. We also call our preprocess_image function on the input image to prepare it for classification by ResNet.
With our image preprocessed, we can load ResNet and classify the image:
# load the pre-trained ResNet50 model
print("[INFO] loading pre-trained ResNet50 model...")
model = ResNet50(weights="imagenet")
# make predictions on the input image and parse the top-3 predictions
print("[INFO] making predictions...")
predictions = model.predict(preprocessedImage)
predictions = decode_predictions(predictions, top=3)[0]
On Line 39 we load ResNet from disk with weights pre-trained on the ImageNet dataset.
Lines 43 and 44 make predictions on our pre-procssed image, which we then decode using the decode_predictions helper function in Keras/TensorFlow.
Let’s now loop over the top-3 predictions from the network and display the class labels:
# loop over the top three predictions
for (i, (imagenetID, label, prob)) in enumerate(predictions):
# print the ImageNet class label ID of the top prediction to our
# terminal (we'll need this label for our next script which will
# perform the actual adversarial attack)
if i == 0:
print("[INFO] {} => {}".format(label, get_class_idx(label)))
# display the prediction to our screen
print("[INFO] {}. {}: {:.2f}%".format(i + 1, label, prob * 100))
Line 47 begins a loop over the top-3 predictions.
If this is the first prediction (i.e., the top-1 prediction), we display the human-readable label to our terminal and then look up the ImageNet integer index of the corresponding label using our get_class_idx function.
We also display the top-3 labels and corresponding probability to our terminal.
The final step is to draw the top-1 prediction on the output image:
# draw the top-most predicted label on the image along with the
# confidence score
text = "{}: {:.2f}%".format(predictions[0][1],
predictions[0][2] * 100)
cv2.putText(output, text, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
The output image is displayed to our terminal until the window opened by OpenCV is clicked on and a key pressed.
Non-adversarial image classification results
We are now ready to perform basic image classification (i.e., no adversarial attack) with ResNet.
Start by using the “Downloads” section of this tutorial to download the source code and example images.
From there, open up a terminal and execute the following command:
$ python predict_normal.py --image pig.jpg [INFO] loading image... [INFO] loading pre-trained ResNet50 model... [INFO] making predictions... [INFO] hog => 341 [INFO] 1. hog: 99.97% [INFO] 2. wild_boar: 0.03% [INFO] 3. piggy_bank: 0.00%

Here you can see that we have classified an input image of a pig, with 99.97% confidence.
Additionally, take note of the “hog” ImageNet label ID (341) — we’ll be using this class label ID in the next section, where we will perform an adversarial attack on the hog input image.
Implementing adversarial images and attacks with Keras and TensorFlow
We will now learn how to implement adversarial attacks with Keras and TensorFlow.
Open up the generate_basic_adversary.py file in our project directory structure, and insert the following code:
# import necessary packages from tensorflow.keras.optimizers import Adam from tensorflow.keras.applications import ResNet50 from tensorflow.keras.losses import SparseCategoricalCrossentropy from tensorflow.keras.applications.resnet50 import decode_predictions from tensorflow.keras.applications.resnet50 import preprocess_input import tensorflow as tf import numpy as np import argparse import cv2
We start by importing our required Python packages on Lines 2-10. You’ll notice that we are once again using the ResNet50 architecture with its corresponding preprocess_input function (for preprocessing/scaling input images) and decode_predictions utility to decode output predictions and display the human-readable ImageNet labels.
The SparseCategoricalCrossentropy computes the categorical cross-entropy loss between the labels and predictions. By using the sparse version implementation of categorical cross-entropy, we do not have to explicitly one-hot encode our class labels like we would if we were using scikit-learn’s LabelBinarizer or Keras/TensorFlow’s to_categorical utility.
Just like we had a preprocess_image utility in our predict_normal.py script, we also need one for this script as well:
def preprocess_image(image): # swap color channels, resize the input image, and add a batch # dimension image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = cv2.resize(image, (224, 224)) image = np.expand_dims(image, axis=0) # return the preprocessed image return image
This implementation is identical to the one above with the exception of leaving out the preprocess_input function call — you’ll see why we are leaving out that call once we start constructing our adversarial image.
Next up, we have a simple helper utility, clip_eps:
def clip_eps(tensor, eps): # clip the values of the tensor to a given range and return it return tf.clip_by_value(tensor, clip_value_min=-eps, clip_value_max=eps)
The goal of this function is to accept an input tensor and then clip any values inside the input to the range [-eps, eps].
The clipped tensor is then returned to the calling function.
We now arrive at the generate_adversaries function, which is the meat of our adversarial attack:
def generate_adversaries(model, baseImage, delta, classIdx, steps=50): # iterate over the number of steps for step in range(0, steps): # record our gradients with tf.GradientTape() as tape: # explicitly indicate that our perturbation vector should # be tracked for gradient updates tape.watch(delta)
The generate_adversaries method is the workhorse of our script. This function accepts four required parameters, including an optional fifth one:
modelbaseImagemodelto misclassify it.deltabaseImage, ultimately causing the misclassification. We’ll update thisdeltavector by means of gradient descent.classIdxpredict_normal.pyscript.steps50steps).
Line 29 starts a loop over our number of steps.
We then use GradientTape to record our gradients. Calling the .watch method of the tape explicitly indicates that our perturbation vector should be tracked for updates.
We can now construct our adversarial image:
# add our perturbation vector to the base image and
# preprocess the resulting image
adversary = preprocess_input(baseImage + delta)
# run this newly constructed image tensor through our
# model and calculate the loss with respect to the
# *original* class index
predictions = model(adversary, training=False)
loss = -sccLoss(tf.convert_to_tensor([classIdx]),
predictions)
# check to see if we are logging the loss value, and if
# so, display it to our terminal
if step % 5 == 0:
print("step: {}, loss: {}...".format(step,
loss.numpy()))
# calculate the gradients of loss with respect to the
# perturbation vector
gradients = tape.gradient(loss, delta)
# update the weights, clip the perturbation vector, and
# update its value
optimizer.apply_gradients([(gradients, delta)])
delta.assign_add(clip_eps(delta, eps=EPS))
# return the perturbation vector
return delta
Line 38 constructs our adversary image by adding the delta perturbation vector to the baseImage. The result of this adding is passed through ResNet50’s preprocess_input function to scale and normalize the resulting adversarial image.
From there, the following takes place:
- Line 43 takes our
modeland makes predictions on the newly constructedadversary. - Lines 44 and 45 calculate the loss with respect to the original
classIdx(i.e., the integer index of the top-1 ImageNet class label, which we obtained by runningpredict_normal.py). - Lines 49-51 show our resulting
lossevery five steps.
Outside of the with statement now, we calculate the gradients of the loss with respect to our perturbation vector (Line 55).
We can then update the delta vector and clip and values that fall outside the [-EPS, EPS] range.
Finally, we return the resulting perturbation vector to the calling function — the final delta value will allow us to construct the adversarial attack used to fool our model.
With the workhorse of our adversarial script implemented, let’s move on to parsing our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to original input image")
ap.add_argument("-o", "--output", required=True,
help="path to output adversarial image")
ap.add_argument("-c", "--class-idx", type=int, required=True,
help="ImageNet class ID of the predicted label")
args = vars(ap.parse_args())
Our adversarial attack Python script requires three command line arguments:
--input: The path to the input image (i.e.,pig.jpg) residing on disk.--output: The output adversarial image after constructing the attack (adversarial.png)--class-idx: The integer class label index from the ImageNet dataset. We obtained this value by runningpredict_normal.pyin the “Non-adversarial image classification results” section of this tutorial.
We can now perform a couple of initializations and load/preprocess our --input image:
# define the epsilon and learning rate constants
EPS = 2 / 255.0
LR = 0.1
# load the input image from disk and preprocess it
print("[INFO] loading image...")
image = cv2.imread(args["input"])
image = preprocess_image(image)
Line 76 defines our epsilon (EPS) value used for clipping tensors when constructing the adversarial image. An EPS value of 2 / 255.0 is a standard value used in adversarial publications and tutorials (the following guide is also helpful if you’re interested in learning more about this “default” value).
We then define our learning rate on Line 77. A value of LR = 0.1 was obtained by empirical tuning — you may need to update this value when constructing your own adversarial images.
Lines 81 and 82 load our input image from disk and preprocess it using our preprocess_image helper function.
Next, we can load our ResNet model:
# load the pre-trained ResNet50 model for running inference
print("[INFO] loading pre-trained ResNet50 model...")
model = ResNet50(weights="imagenet")
# initialize optimizer and loss function
optimizer = Adam(learning_rate=LR)
sccLoss = SparseCategoricalCrossentropy()
Line 86 loads the ResNet50 model, pre-trained on the ImageNet dataset.
We’ll use the Adam optimizer, along with the sparse categorical-loss implementation, when updating our perturbation vector.
Let’s now construct our adversarial image:
# create a tensor based off the input image and initialize the
# perturbation vector (we will update this vector via training)
baseImage = tf.constant(image, dtype=tf.float32)
delta = tf.Variable(tf.zeros_like(baseImage), trainable=True)
# generate the perturbation vector to create an adversarial example
print("[INFO] generating perturbation...")
deltaUpdated = generate_adversaries(model, baseImage, delta,
args["class_idx"])
# create the adversarial example, swap color channels, and save the
# output image to disk
print("[INFO] creating adversarial example...")
adverImage = (baseImage + deltaUpdated).numpy().squeeze()
adverImage = np.clip(adverImage, 0, 255).astype("uint8")
adverImage = cv2.cvtColor(adverImage, cv2.COLOR_RGB2BGR)
cv2.imwrite(args["output"], adverImage)
Line 94 constructs a tensor from our input image, while Line 95 initializes delta, our perturbation vector.
To actually construct and update the delta vector, we make a call to generate_adversaries, passing in our ResNet50 model, input image, perturbation vector, and integer class label index.
The generate_adversaries function runs, updating the delta pertubration vector along the way, resulting in deltaUpdated, the final noise vector.
We construct our final adversarial image (adverImage) on Line 105 by adding the deltaUpdated vector to baseImage.
Afterward, we proceed to post-process the resulting adversarial image by:
- Clipping any values that fall outside the range [0, 255]
- Converting the image to an unsigned 8-bit integer (so that OpenCV can now operate on the image)
- Swapping color channel ordering from RGB to BGR
After the above preprocessing steps, we write the output adversarial image to disk.
The real question is, can our newly constructed adversarial image fool our ResNet model?
The next code block will address that question:
# run inference with this adversarial example, parse the results,
# and display the top-1 predicted result
print("[INFO] running inference on the adversarial example...")
preprocessedImage = preprocess_input(baseImage + deltaUpdated)
predictions = model.predict(preprocessedImage)
predictions = decode_predictions(predictions, top=3)[0]
label = predictions[0][1]
confidence = predictions[0][2] * 100
print("[INFO] label: {} confidence: {:.2f}%".format(label,
confidence))
# draw the top-most predicted label on the adversarial image along
# with the confidence score
text = "{}: {:.2f}%".format(label, confidence)
cv2.putText(adverImage, text, (3, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 255, 0), 2)
# show the output image
cv2.imshow("Output", adverImage)
cv2.waitKey(0)
We once again construct our adversarial image on Line 113 by adding the delta noise vector to our original input image, but this time we call ResNet’s preprocess_input utility on it.
The resulting preprocessed image is passed through ResNet, after which we grab the top-3 predictions and decode them (Lines 114 and 115).
We then grab the label and corresponding probability/confidence with the top-1 prediction and display these values to our terminal (Lines 116-119).
The final step is to draw the top prediction on our output adversarial image and display it to our screen.
Results of adversarial images and attacks
Ready to see an adversarial attack in action?
Make sure you used the “Downloads” section of this tutorial to download the source code and example images.
From there, you can open up a terminal and execute the following command:
$ python generate_basic_adversary.py --input pig.jpg --output adversarial.png --class-idx 341 [INFO] loading image... [INFO] loading pre-trained ResNet50 model... [INFO] generating perturbation... step: 0, loss: -0.0004124982515349984... step: 5, loss: -0.0010656398953869939... step: 10, loss: -0.005332294851541519... step: 15, loss: -0.06327803432941437... step: 20, loss: -0.7707189321517944... step: 25, loss: -3.4659299850463867... step: 30, loss: -7.515471935272217... step: 35, loss: -13.503922462463379... step: 40, loss: -16.118188858032227... step: 45, loss: -16.118192672729492... [INFO] creating adversarial example... [INFO] running inference on the adversarial example... [INFO] label: wombat confidence: 100.00%
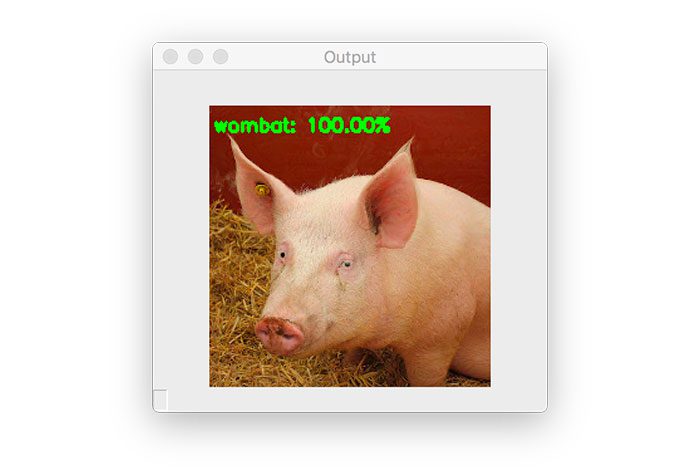
Our input pig.jpg, which was correctly classified as “hog” in the previous section is now labeled as a “wombat”!
I’ve placed the original pig.jpg image next to the adversarial image generated by our generate_basic_adversary.py script below:
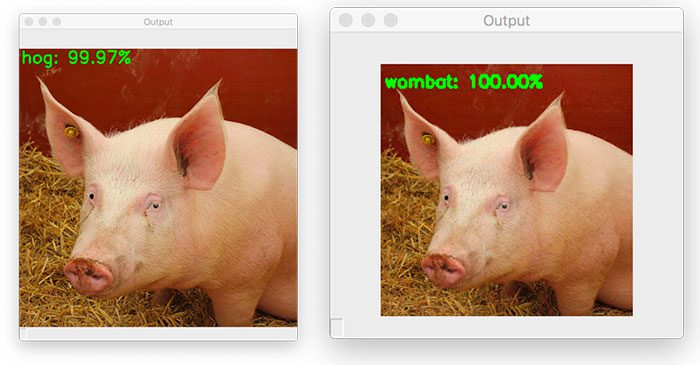
On the left is the original hog image, while on the right we have the output adversarial image, which is incorrectly classified as a “wombat”.
As you can see, there is no perceptible difference between the two images — our human eyes can see the difference between these two images, but to ResNet, they are totally different.
That’s all well and good, but we clearly don’t have control over the final class label in the adversarial image. That raises the question:
Is it possible to control what the final output class label of the input image is? The answer is yes — and I’ll be covering that question in next week’s tutorial.
I’ll conclude by saying that it’s easy to get scared of adversarial images and adversarial attacks if you let your imagination get the best of you. But as we’ll see in a later tutorial on PyImageSearch, we can actually defend against these types of attacks. More on that later.
Credits
This tutorial would not have been possible without the research of Goodfellow, Szegedy, and many other deep learning researchers.
Additionally, I want to call out that the implementation used in today’s tutorial is inspired by TensorFlow’s official implementation of the Fast Gradient Signed Method. I strongly suggest you take a look at their example, which does a fantastic job explaining the more theoretical and mathematically motivated aspects of this tutorial.
What’s next?

Today’s tutorial was the first time we have formally covered both non-adversarial image classification and adversarial images and attacks, with Keras and TensorFlow.
If you don’t already know the fundamentals of deep learning, OR you have begun to envision the creation (and destruction) of your own personal ImageNet dataset – now is the perfect time for you to invest in your education! To get your head start, I personally suggest you read my book Deep Learning for Computer Vision with Python.
I crafted my book so that it perfectly blends theory with code implementation, ensuring you can master:
- Deep learning fundamentals and theory without unnecessary mathematical fluff. I present the basic equations and back them up with code walkthroughs that you can implement and easily understand. You don’t need a degree in advanced mathematics to understand this book.
- How to implement your own custom neural network architectures. Not only will you learn how to implement state-of-the-art architectures, including ResNet, SqueezeNet, etc., but you’ll also learn how to create your own custom CNNs.
- How to train CNNs on your own datasets. Most deep learning tutorials don’t teach you how to work with your own custom datasets. Mine do. You’ll be training CNNs on your own datasets in no time.
- Object detection (Faster R-CNNs, Single Shot Detectors, and RetinaNet) and instance segmentation (Mask R-CNN). Use these chapters to create your own custom object detectors and segmentation networks.
You’ll also find answers and proven code recipes to:
- Create and prepare your own custom image datasets for image classification, object detection, and segmentation
- Work through hands-on tutorials (with lots of code) that not only show you the algorithms behind deep learning for computer vision but their implementations as well
- Put my tips, suggestions, and best practices into action, ensuring you maximize the accuracy of your models
Beginners and experts alike tend to resonate with my no-nonsense teaching style and high quality content.
If you’re on the fence about taking the next step in your computer vision, deep learning, and artificial intelligence education, be sure to read my Student Success Stories. My readers have gone on to excel in their careers — you can too!
If you’re ready to begin, purchase your copy today. And if you aren’t convinced yet, I’d be happy to send you the full table of contents + sample chapters — simply click here. You can also browse my library of other book and course offerings.
Summary
In this tutorial, you learned about adversarial attacks, how they work, and the threat they pose to a world becoming more and more reliant on Artificial Intelligence and deep neural networks.
We then implemented a basic adversarial attack algorithm using the Keras and TensorFlow deep learning libraries.
Using adversarial attacks, we can purposely perturb an input image such that:
- The input image is misclassified
- However, to the human eye, the perturbed image looks identical to the original
However, using the method applied here today, we have absolutely no control over what the final class label of the image is — all we’re doing is creating and embedding a noise vector that causes the deep neural network to misclassify the image.
But what if we could control what the final target class label is? For example, is it possible to take an image of a “dog” and construct an adversarial attack such that the Convolutional Neural Network thinks the image is a “cat”?
The answer is yes — and we’ll be covering that exact same topic in next week’s tutorial.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!
The post Adversarial images and attacks with Keras and TensorFlow appeared first on PyImageSearch.






















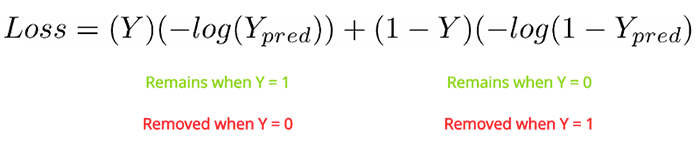
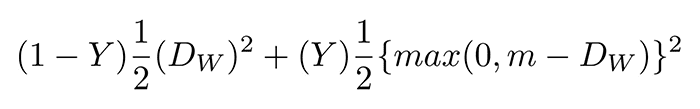
 value is our label. It will be
value is our label. It will be  if the image pairs are of the same class, and it will be
if the image pairs are of the same class, and it will be  if the image pairs are of a different class.
if the image pairs are of a different class. variable is the Euclidean distance between the outputs of the sister network embeddings.
variable is the Euclidean distance between the outputs of the sister network embeddings. , minus the distance.
, minus the distance.






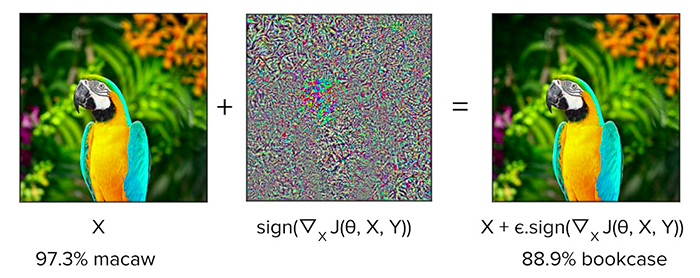

 : Our output adversarial image
: Our output adversarial image : The original input image
: The original input image : The ground-truth label of the input image
: The ground-truth label of the input image : Small value we multiply the signed gradients by to ensure the perturbations are small enough that the human eye cannot detect them but large enough that they fool the neural network
: Small value we multiply the signed gradients by to ensure the perturbations are small enough that the human eye cannot detect them but large enough that they fool the neural network : Our neural network model
: Our neural network model : The loss function
: The loss function






 99% accuracy with Yugioh card recognition.
99% accuracy with Yugioh card recognition. 


 98% accuracy on the adversarial images after fine-tuning.
98% accuracy on the adversarial images after fine-tuning.